Introducing: The OWA Agent Architecture
A scalable framework for reducing AI slop in practice and production

Introduction
Ask anyone using ChatGPT, Claude, or Gemini to build something non-trivial, and you’ll likely notice the same pattern: the first response sounds confident, the output looks plausible, and then the details fall apart. The instinct is to fix this through iterative prompting our prompt engineering. The user rewrites instructions until the model finally understands what they mean.
However, that approach treats the problem like a communication failure, and it’s actually a structural one. A single LLM call has no mechanism to question its own work, revisit assumptions, or iterate towards a better answer. It produces a draft and steadily moves on. Real knowledge work doesn’t happen this way — humans learn through iteration and friction, and the models we use should do the same.
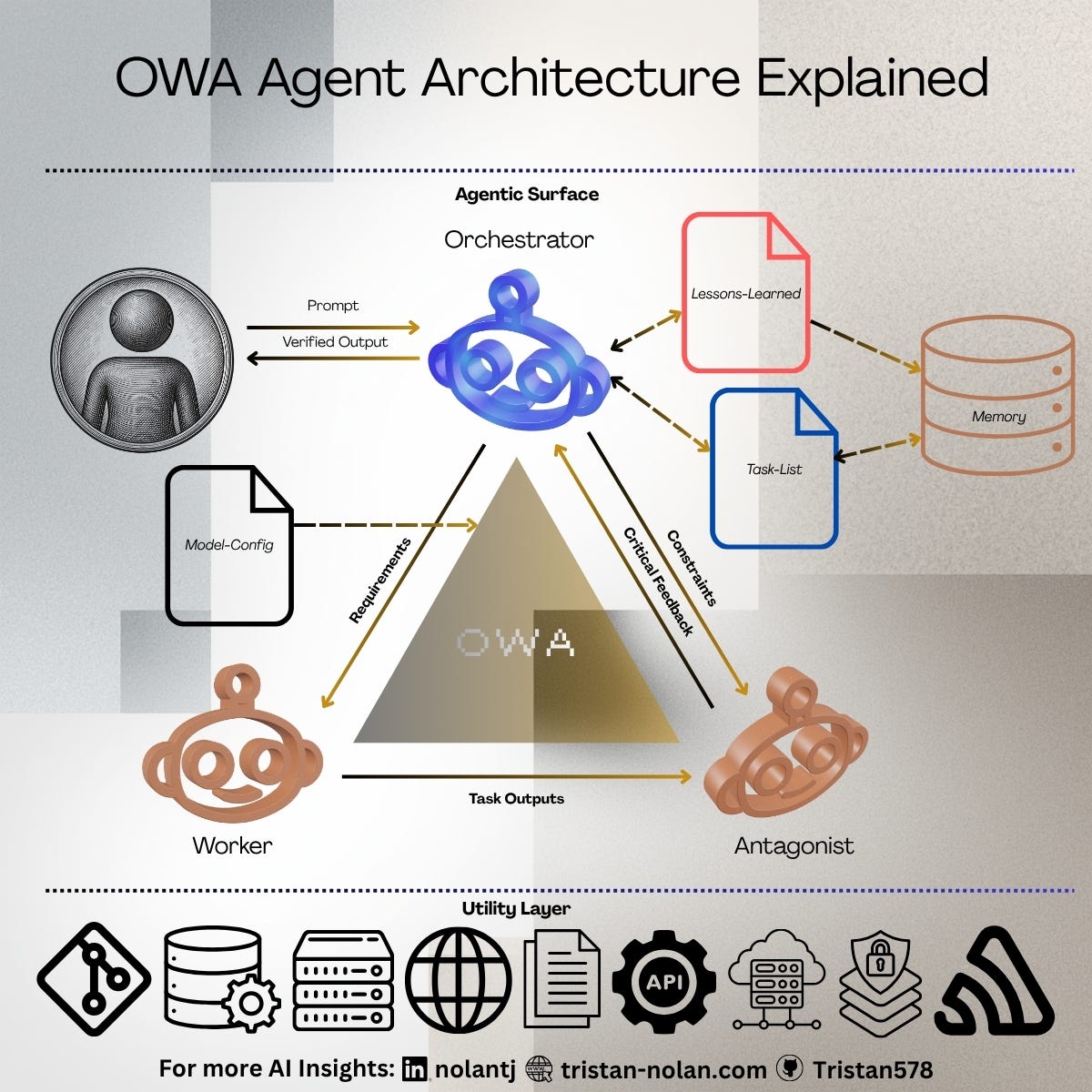
To address the cognitive gap between what a user expects an AI to do and an LLM’s actual zero-shot capabilities, I constructed the OWA (Orchestrator, Worker, Antagonist) Agent Architecture. Today’s models have a staggering grasp of software engineering, audio and visual generation, and computer use, but human understanding is generally not held in zeroes and ones. We require systems that reflect the iterative nature of actual knowledge work.
OWA embeds that iterative cycle directly into the system: agents that produce the work, challenge that work, and manage the work plan effectively and iteratively until quality gates are met. OWA is framed around the idea that a stronger process matters more than the individual prompt.
The Problem with Sycophancy
I have had my fill of “yes-man” interactions. Statements like “You’re absolutely right!” do more to irritate me than correct my confidence or understanding. This tendency runs deep in almost all commercially available and open-source models today.
This is a well-documented architectural flaw. Research from Anthropic (Sharma et al., 2023, Towards Understanding Sycophancy in Language Models) highlights that LLMs are statistically predisposed to agree with a user’s stated beliefs or prematurely validate user-provided code, even when that code is objectively incorrect. The models are optimized for helpfulness and harmlessness, which often degrades into blind agreement.
Knowledge work is not done in a silo. Research cannot be successfully completed in a world where we are absolutely right all of the time. Humans learn through iteration and friction, and the models we use must do the same.
The OWA Framework Defined
In practice, most human interaction with AI occurs through chatbots or dedicated agents handling tasks. In a traditional environment, the human acts as an orchestrator of sorts and tasks a worker with a job. This falls apart when context is misunderstood, prompts are too broad, or specific guardrails must be met. LLMs are good at reading the beginning and end of a book, but are decisively bad at picking up the messy middle in long-running tasks involving large amounts of context.
OWA introduces a multi-agent adversarial loop to manage this exact problem.